
概述
词法分析是编译阶段的第一步。这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。词法分析程序实现这个任务。词法分析程序可以使用Lex等工具自动生成。
本项目实现了一个简单C语言词法分析器。
软件首页:
项目主页:
项目特性
支持十进制数、八进制数、标识符、关键字、操作符、分隔符等多种词素
支持文件导入和代码编写两种输入方式
算法和UI通过特定的接口实现二者之间的低耦合
项目结构
Lexer-- com.kinegratii.lexer 主包 |--- Lexer.java 项目启动类 |--- MainFrame.java 界面类 |--- SoftwareInfo.java 软件信息常量定义 -- com.kinegratii.core 词法分析包 |--- Analyzer.java 词法分析器 |--- LexerAnalysisProccessCallback.java 回调接口 -- com.kinegratii.token 词素包 |--- DoubleToken.java 浮点数 |--- DotToken.java 分隔符 |--- IdentifiterToken.java 标志符 |--- IntegerToken.java 整型数字 |--- ReservedToken.java 关键字 -- com.kinegatii.utils 工具包 |--- BareBonesBrowserLaunch.java 调用浏览器
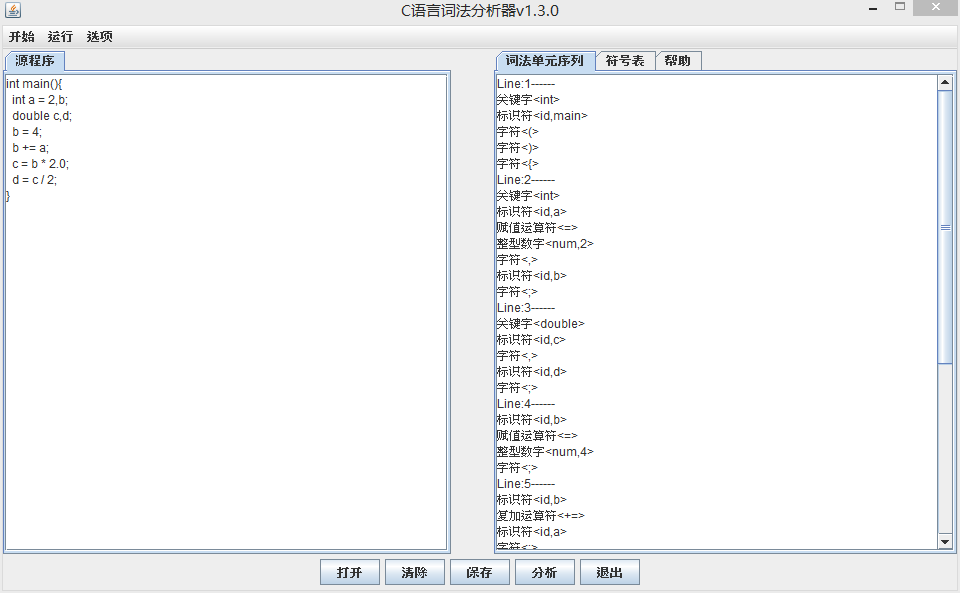
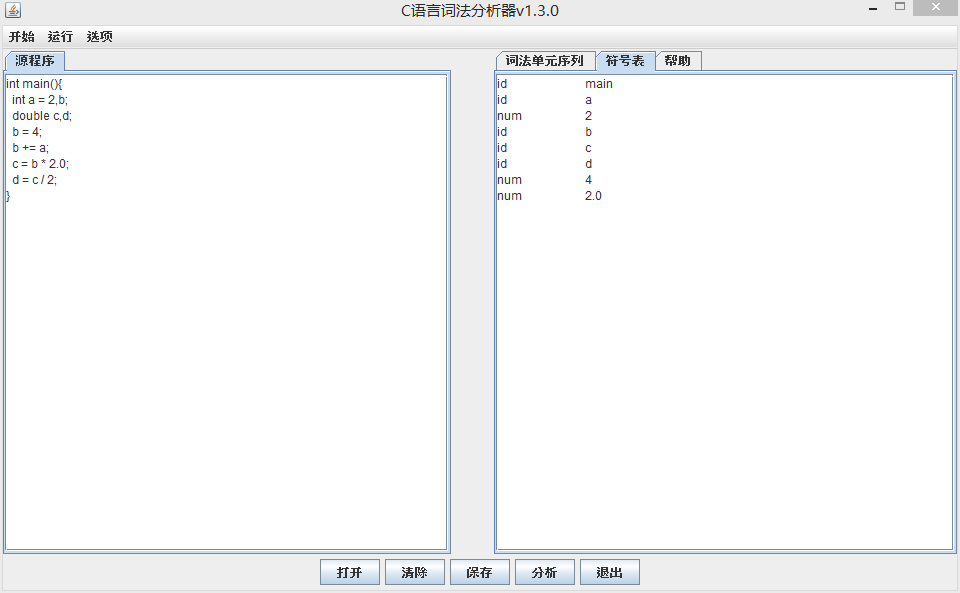
项目截图
词法单元序列
符号表
项目开发
本项目是《编译课程》的一个实践项目,初步代码完成于2012年4月,也经历过几次小的变动,版本到了1.2.4(那时版本比较随意)。前些时间进行了整体上的重构,就有了这次的v1.3.0 版本。
v1.3.0 2014-09-24
重构整个项目,根据职责划分包和类,实现算法和UI的低耦合
去掉了语言改造部分
所谓语言改造部分,就是这个分析器当中一些自定义的规则,比如有连续下划线的标识符应该只保留一个,如“a__b" => "a_b"等等。这些都不是标准分析器的一部分,之所以有这么个东西在,是为了防止全文复制,每年的语言改造都不一样,即使拿到了往届的代码也要改动一下,这就要熟悉整个项目代码了。
后续计划
支持通过配置Analyzer实现自定义语言改造部分,这主要指代码级别上。基本要求是可配置性、通用接口。
目前的处理回调接口还比较简单,可以考虑在接口中多暴露一些分析器的数据。